Whitepaper
Syntience - Decentralized AI Network
Harnessing Global Computational Power through P2P Networks for AI
Interstellar Research Pte Ltd
Initial draft: 26 September 2023
Revision: 10th January 2024
1. Abstract
In the realm of Artificial Intelligence, the recent proliferation of deep learning models, characterized by their profound neural networks and large weights, has advanced capabilities in areas like image generation and query resolution. However, the training of these models is constrained by specialized hardware availability, monopolistic control over critical infrastructure, and the centralization of AI power within major corporations. This paper introduces a decentralized, peer-to-peer computing network designed to address these challenges by harnessing underutilized computational resources globally. Integrating distributed computing techniques and a novel digital token incentivization mechanism, the system promotes open-source model development, ensuring transparency, security, and accessibility. We delve into the architecture encompassing data science considerations, distributed computing strategies, Byzantine fault tolerance, and token-based incentivization. Our proposed solution aims to democratize access to AI training and inference, fostering a more equitable AI ecosystem.
2. Problem Statement
Recently, there has been a proliferation of deep learning models exhibiting remarkable capabilities, including answering queries, writing computer programs, and generating visuals. These models are founded on deep neural networks with an extensive number of weights, allowing them to achieve unparalleled performance compared to their predecessors. They are now widely employed to produce imaginative and lifelike images, support software developers, assist content creators, and more. Such advancements are instrumental in elevating productivity and the overall quality of life.
2.1 Limited Access to Specialized Hardware
Training these models necessitates a robust infrastructure, typically involving numerous servers in data centers outfitted with specialized hardware, including GPUs or TPUs. A select few manufacturers dominate this hardware market, exercising control over distribution and pricing. Consequently, acquiring these devices at reasonable prices becomes challenging, especially when purchasing smaller quantities.
2.2 Cloud Computing Predicaments
The constraints in direct hardware acquisition often compel individuals and smaller entities to turn to cloud computing for renting the necessary infrastructure. However, even this domain is predominantly governed by a handful of major corporations. The surging interest in generative AI has further intensified the demand, leading to a noticeable shortage in infrastructure availability. Cloud providers often necessitate long-term commitments for server access. Consequently, procuring adequate hardware resources for training expansive models is increasingly challenging for individuals and smaller organizations.
These corporate giants serve as gatekeepers to this groundbreaking technology. Given the transformative potential of this technology, it is imperative to democratize access to training and inference—failure to do so risks deepening existing societal inequalities.
2.3 Challenges in Harnessing Distributed Computing
Across the globe, vast computational power remains untapped, encompassed by devices such as gaming computers, workstations, and computers within academic computer labs within universities. Despite their potential, many of these resources are underutilized. Leveraging these resources to train large models presents an intriguing possibility; however, several significant challenges prevent its widespread adoption:
Network Limitations: Devices connected via the internet suffer from higher latency and reduced bandwidth compared to the localized networks in data centers. [1]
Hardware Constraints: Many of these computers are not built to industry specifications, often possessing limited CPU and GPU memory capacities. Some might even lack a GPU entirely, making them ill-suited for accommodating extensive language models. This results in a drastic reduction in training efficiency. Most GPUs have at most 8 to 12 GB of video RAM, which is only useful for training very small models. [2]
Security and Trust Concerns: Executing computations on unverified or trustless systems introduces many risks. These systems are susceptible to malicious activities, including data poisoning, selfish mining, incorrect computations, and unscheduled downtimes. [3]
Lack of Incentives: Without a direct incentive mechanism, "volunteer computing" struggles to attract participants willing to allocate their computing power for shared tasks.
Addressing these challenges might make it feasible to harness the distributed computational power more effectively for large-scale machine-learning endeavors.
2.4 Infrastructure Challenges for Independent Research and Public Good
The lack of accessible and affordable infrastructure is particularly pronounced for research institutions and independent scholars aiming to develop open-source models for societal benefit. Such entities often lack the necessary affiliations or leverage with major infrastructure providers and are frequently constrained by financial resources, making hardware acquisition or rental infeasible. This limitation further accentuates the centralization of power in training and governing large AI models.
Predominantly, it is the corporate giants that exercise discretion over crucial aspects, such as:
- The selection of training data
- Choice of modality
- Introduction of biases
- Implementation of censorship
- Determination of user access and restrictions
- And the establishment of pricing structures.
More often than not, these corporations maintain their models' proprietary nature, prioritizing profit motives over open access and transparency. Hence, there is an urgent need for a democratized, cost-effective infrastructure that would empower researchers to train open-source models. Such models should be free from the above mentioned constraints, ensuring unbiased and unbridled advancement in AI.
3. Syntience- Decentralized Framework for AI Model Training and Inference
In this paper, we will introduce a decentralized, fault-tolerant, censorship-resistant, permissionless, peer-to-peer (P2P) computing network called “Syntience”. This network is designed to leverage internet-connected commodity hardware, facilitating the training and inference tasks associated with large AI models.
AI models can often be decomposed into modular components by their inherent design. Such decomposition allows these models to be distributed across standard commercial computers, optimizing computational resources. After this distribution, a P2P communication protocol is established to ensure efficient data exchange and coordination among these computational units.
A byzantine fault-tolerant consensus mechanism is introduced to safeguard the network's operations and deter malicious intents. With the help of probabilistic computation verification, proof of stake, cryptocurrency token-based penalty and reward mechanism and blockchain-based smart contracts, honest behavior is rewarded, and malicious behavior is penalized. The blockchain's transparency ensures that all network participant activities are recorded and verifiable.
Engagement with the network for training, fine-tuning, or inference necessitates users to provide specific parameters, including datasets, model weights, and hyperparameters. Users must adhere to a predefined fee structure in exchange for the network's computational services. These accrued fees are subsequently distributed among the network participants who contribute their computational resources.
An integral feature of this framework is its compatibility with cloud spot instances, also known as "preemptible" instances. Spot VMs are available at much lower prices than the on-demand price for standard VMs. [4] These instances, while cost-effective, are subject to termination based on the cloud provider's operational needs. A comparative analysis in the following figure highlights the cost advantages of spot instances against their standard and reserved counterparts.
| Model | GPUs | GPU Memory | GPU Price (USD) | 1 Year Commitment (USD) | 3 Year Commitment (USD) | Spot Price (USD) |
|---|---|---|---|---|---|---|
| NVIDIA T4 | 1 GPU | 16 GB GDDR6 | $0.35 | $0.22 | $0.16 | $0.14 |
| NVIDIA P4 | 1 GPU | 8 GB GDDR5 | $0.60 | $0.38 | $0.27 | $0.24 |
| NVIDIA V100 | 1 GPU | 16 GB HBM2 | $2.48 | $1.56 | $1.12 | $0.78 |
| NVIDIA P100 | 1 GPU | 16 GB HBM2 | $1.46 | $0.92 | $0.66 | $0.58 |
| NVIDIA K80 | 1 GPU | 12 GB GDDR5 | $0.45 | $0.28 | N/A | $0.18 |
| NVIDIA T4 Virtual Workstation | 1 GPU | 16 GB GDDR6 | $0.55 | $0.42 | $0.36 | $0.31 |
| NVIDIA P4 Virtual Workstation | 1 GPU | 8 GB GDDR5 | $0.80 | $0.58 | $0.47 | $0.42 |
| NVIDIA P100 Virtual Workstation | 1 GPU | 16 GB HBM2 | $1.66 | $1.12 | $0.86 | $0.63 |
Figure 1. Comparison between spot and reserved pricing for GCP in Iowa (us-central-1) zone, as of 27 September 2023 [5]
The proposed framework is structured to integrate a broad spectrum of computational assets. Entities possessing industrial-grade hardware, computing clusters, or idle reserved instances can contribute these resources to the network. By doing so, they enhance the network's computational capabilities and, in return, receive incentives. Notably, the framework's design is compatible with various hardware configurations, even those reliant solely on CPUs, underscoring the versatility of the proposed approach.
3.1 Empowering Open-Source Model Development through the Decentralized Network
The proposed network seeks to foster open-source model development by emphasizing three core principles: transparency, security, and accessibility.
3.1.1 Decentralized Training with Complete Transparency��
The models are trained in a decentralized fashion within the network. Each training step and subsequent modification are recorded transparently, providing a detailed account of the model's progression. This transparency is enhanced by the inclusion of a cryptographic audit trail, ensuring both traceability and accountability throughout the training process and dataset used.
3.1.2 Bias Verification through Cryptographic Audit Trails
Beyond documenting the model's development phases, the cryptographic audit trail serves a dual purpose by enabling the examination of potential biases in the training data. Given the increasing focus on unbiased AI research, this feature provides a mechanism for objective assessment of model neutrality.
3.1.3 Token Mechanism for Infrastructure Incentivization
A significant impediment in AI research is the substantial infrastructure costs. The introduction of a token mechanism in the network addresses this challenge. Infrastructure contributors are compensated via the network's token, eliminating the need for external researchers to incur these overheads. This approach aims to cultivate a conducive environment, particularly benefiting researchers with constrained financial resources, thereby promoting broader engagement in open-source AI model development.
3.2 Existing Solutions
Currently, there are a few projects that have tried to solve the problem. There are web 2.0 GPU rental marketplaces like vast.ai, runpod, etc, where anyone can rent their GPUs. There are some marketplaces based on blockchain infrastructure, such as Akasha network and io.net. However, since most of these GPUs are hosted by individuals in their homes and connected with each other through the internet, it is not feasible to use them to train or infer on large models. Since the models will not fit in individual machines, running model parallelism over the internet is not a solved problem. However, these GPUs can be utilized by Syntience validators to run their nodes and run arbitrarily large models over the internet. Hence, these products are complementary rather than competing.
4. Architecture
Validators can decide if they would like to participate in open-source model training, normally paid training jobs, or both.
The proposed system's architecture is structured into four primary components:
- Data Science
- Decentralized computing
- Fault tolerance
- Token mechanism design
4.1 Data Science
The system is initially tailored to support models developed using the PyTorch library. This design choice ensures compatibility with various contemporary AI research workflows. While PyTorch is the primary focus currently, provisions have been made to extend support to other libraries in subsequent iterations. Specifically, the network facilitates PyTorch's forward and backward propagation computations across the internet.
There is a possibility for directly integrating prevalent open-source models such as LLama 2 and Stable Diffusion. This integration allows users to perform fine-tuning and inference tasks without additional configurations. Furthermore, this paves the way for training models from the ground up based on these established model architectures.
It is imperative to note that for efficient computation across the internet, the selection of hyperparameters and the overall model architecture warrant meticulous consideration to ensure optimal performance.
4.2 Distributed Computing
To establish a distributed computational environment, our architecture integrates the capabilities of libp2p for distributed hash tables (DHT), TLS, and peer-to-peer communication. Models can be trained in various configurations. Some of the examples are suggested below.
4.2.1 Data Parallel Training
Under this configuration, individual devices operate on the entire model but process distinct data portions. After a specific number of epochs, the gradients are averaged. To ensure model consistency and mitigate potential drift in learning, there is an option to average model weights at predetermined intervals. Importantly, these operations are decentralized, providing resilience and fault tolerance in the distributed setup.
4.2.2 Model Parallel Training
This approach is necessitated when the size of a model's weights surpasses the memory constraints of a single device. To address this, the model is systematically divided into discrete partitions, and each partition is allocated to a separate device. Since devices are dispersed and connected over the internet, strategic planning for partitioning becomes crucial. The aim is to reduce communication overheads, which can become performance bottlenecks if not appropriately addressed.
4.2.3 Combined Model and Data Parallel Training
Combining both configurations mentioned above can offer advantages in training and inference efficiency in specific scenarios. This setup leverages the strengths of both data and model parallel strategies.
4.2.4 Mixture of Experts
Beyond traditional configurations, our system is also designed to accommodate the 'Mixture of Experts' architecture, accommodating traditional MoE gating functions [6] or the modified "Switch Transformer" gating function [7]. The gating function and the overall architecture of the model need to be appropriately designed to avoid the communication bottlenecks and computational bottlenecks of the device running the gating function. Also, due to the sparse nature of the model, the computation required per device may be lower than other configurations, which may be suitable for low-cost CPU-only devices.
4.3 Fault Tolerance
In a decentralized computational environment, ensuring fault tolerance is paramount due to the inherent challenges of operating in a trustless domain. Given that no node holds privileged status or implicit trust, there exists a potential for nodes to act adversarially, posing threats to the network's integrity.
The integration of spot instances, susceptible to preemptive termination, further complicates the situation. Additionally, relying on volunteer computing resources introduces unpredictability regarding power supply consistency and potential internet connectivity disruptions. This volatility necessitates a robust strategy to counteract devices' unpredictable performance or unanticipated downtimes.
4.3.1 Byzantine Faults
Byzantine faults, in this context, encompass a diverse range of adversarial behaviors, including but not restricted to:
- Data poisoning or the intentional introduction of inaccurate training data
- Return of erroneous output data
- "Selfish mining," where a node avoids or minimizes its computational contributions
- High-latency communication or unanticipated disconnections from the network
Addressing these challenges is essential for maintaining the reliability and integrity of the proposed distributed computing system.
4.3.2 Mechanism to Address Fault Tolerance
We propose leveraging the butterfly clip algorithm[8] for fault tolerance. The algorithm encompasses several techniques and strategies to counteract adversarial behaviors:
- Gradient Clipping: Utilize the centered clip methodology to prune outlier gradient values. This helps in maintaining the integrity of the model's training process.
- Gradient Averaging: The butterfly all-reduce technique calculates gradient averages collaboratively. This approach optimizes the network's resources by minimizing communication overhead, which is crucial in a distributed setting.
- Node Computation Verification: Computation verification is implemented by selecting a node pseudorandomly and scrutinizing its computations. If there is evidence of malicious behavior, a transparent mechanism allows for submitting a “fraud-proof.” Upon successful verification, the malicious node's stake is "slashed." As an incentive to ensure the network's integrity, the entity—termed the "bounty hunter"—that correctly identifies the dishonest node is awarded. [9,10]
Such mechanisms collectively provide a comprehensive strategy to ensure fault tolerance, enhancing the reliability and trustworthiness of the decentralized network.
4.3.3 Efficient Computation Verification
In a decentralized computational environment, ensuring efficiency is essential. Redundant computations expend unnecessary resources and decelerate the overall network performance.
To address this, avoiding exhaustive recomputation across all nodes is prudent. Instead, a more efficient strategy involves pseudorandom selection of a subset of nodes for computational verification. This approach strikes a balance between ensuring network integrity and optimizing resource usage.
For transparency and verifiability, every node is mandated to disclose several parameters publicly:
- Incoming data
- Outgoing data
- Initial model weights
- Final model weights
This public data ledger can be maintained on platforms such as blockchain, Distributed Hash Tables (DHT), or other peer-to-peer systems, including IPFS or torrent-based technologies.
Nodes are encouraged to allocate a portion of their computational power—approximately between 1/8th to 1/16th—to verify the computations of their peers. This verification process is not solely confined to fully participatory nodes. Nodes termed "bounty hunters," which might lack the bandwidth for primary computational tasks, can engage asynchronously in this verification.
The discovering node can submit proof of the inconsistency if a discrepancy or fault is identified. If a consensus emerges among the majority of nodes about the fault's legitimacy, the offending node faces penalties. This might entail reducing their staked resources and a temporary or permanent reduction in their network participation rights, thus ensuring accountability within the network.
4.4 Incentivization mechanism
An effective incentivization mechanism is essential to ensure honest participation and motivate optimal resource allocation in a decentralized framework.
We suggest the creation and integration of a novel cryptocurrency token.
Entities wishing to engage as infrastructure providers must procure and subsequently commit a minimum quantity of native tokens as stakes. This staking process is collateral, ensuring a vested interest in the system's honest and efficient operation.
At the culmination of every defined "epoch" or computational interval, providers receive compensation through fees and additional tokens that align with the protocol's reward criteria.
If a provider is identified as engaging in Byzantine behavior, stringent measures are triggered by the network. Such a provider will be excluded from the remuneration corresponding to that epoch, and a designated portion of their committed tokens will be slashed as a penal action. This balanced approach of rewards and penalties aims to foster authentic engagement while deterring potential malicious undertakings.
5. Synapse
We have built an open-source tool to train, fine-tune, and perform inference on AI models in a distributed way over the internet. This tool is a proof of concept of the distributed computing and AI model implementation part of this broad project. It does have some fault tolerance such as nodes going offline and becoming non-responsive. In the future, we will add byzantine fault tolerance with blockchain technology integration, which is an essential component of the Syntience design.
Synapse uses the hivemind[11] Python library based on the research paper[12] for distributed AI model training. Hivemind is primarily built for a Mixture Of Expert models; however, in our experiments, we discovered that this family of models is communication-intensive, and there are multiple bottlenecks in the design, especially the server running the gating function.
We utilized hivemind and extended it to support different modes of parallelism, such as model parallel, data-parallel, and hybrid parallel training. We will train a data-parallel model as an example. In the future, we aim to train and release larger models that use data + model parallelism.
5.1 Experimental setup
We used the tiny stories dataset [13], which contains synthetically generated (by GPT-3.5 and GPT-4) short stories that use a small vocabulary. We train a llama block from scratch with 1024 hidden dimensions, 8 attention heads, a vocabulary size of 4096, and a context length of 2048. We use four nodes in different regions on the Google Cloud Platform (us-central1-a, asia-northeast1-c, europe-central2-b, us-east4-b), and split the dataset between three trainers. We use data parallelism across different nodes for training. We train for one epoch on n1-standard-16 machines with 1x Nvidia T4 GPU.
5.2 Results
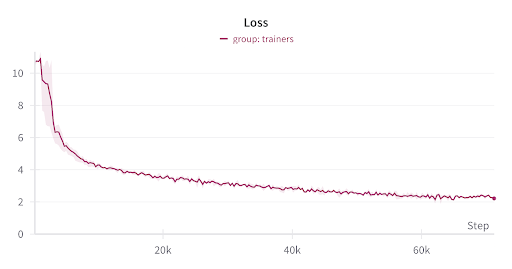
Figure 2: Training loss
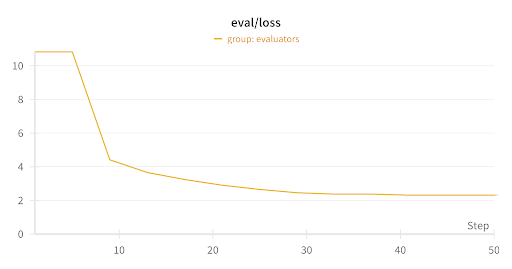
Figure 3: Eval loss
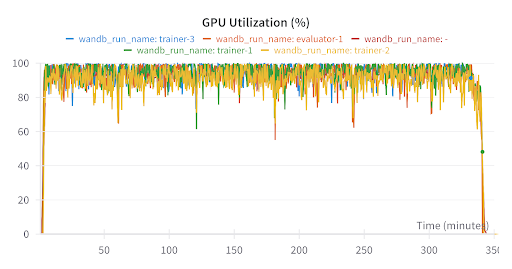
Figure 4: GPU utilization
5.2.1 Sample generation
The family learned a lot about animals and sounds. They all picked them in their hand and went to their friend, the elderly man. They asked him to let his friends cook for him. They made funny faces and laughed and said: "And my friends are so simple. We are in the village and to the people who are safe and share. We want them to be safe. We should not hurt them. We should have listened to this animal. We should show him the animals. They will be very comfortable and safe. They were not hungry and tired. They didn't like the animals. They had to say sorry to each other.Lily and Tom were twins who liked to play with their toys. They had many toys and snacks. They had many toys, but they both liked to make up with their toys and books. One day, they saw a big, dull hat on the floor. It was round and has a handle on it. The red truck wanted to buy the box of the red tie. They opened it and pulled it out. They ran to the tape and pushed it hard. But the box was not normal. The doll fell and hurt.
Figure 5: Sample generation
As we demonstrate, average GPU utilization remains high at around 95% throughout training, even across different regions. With more optimizations, this can be pushed higher across all participating nodes.
6. Conclusion
The rapid advancements in AI and deep learning models have revolutionized various domains, promising transformative capabilities and enhancements in quality of life. However, the complexities of training these models and centralized control over vital infrastructure have presented significant challenges. This research introduced a decentralized, peer-to-peer computing network to mitigate these issues, fostering a more inclusive and transparent environment for AI development. The proposed network democratizes access to AI training and inference and promotes open-source model development by harnessing underutilized global computational resources and integrating a robust token-based incentivization mechanism. Introducing a new native token, a foundational component of the network's incentive structure, ensures honest participation while optimizing resource contribution. Looking ahead, as AI continues to permeate every facet of our lives, decentralized systems like the one proposed here will be paramount in ensuring that the benefits of AI are equitably distributed and its development remains transparent, accessible, and free from undue centralized influence. By building or proof of concept tool “Synapse,” we proved that training models over the internet is feasible with high levels of utilization.
7. References
[1] Tom B Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. arXiv preprint arXiv:2005.14165, 2020.
[2] https://en.wikipedia.org/wiki/List_of_Nvidia_graphics_processing_units#GeForce_40_series
[3] Muhammad Asad, Ahmed Moustafa, and Takayuki Ito, et al Federated Learning Versus Classical Machine Learning: A Convergence Comparison. arXiv preprint arXiv:2107.10976, 2021.
[4]https://cloud.google.com/compute/docs/instances/spot#pricing
[5]https://cloud.google.com/compute/all-pricing#gpus
[6] Max Ryabinin, Anton Gusev, et al. Towards Crowdsourced Training of Large Neural Networks using Decentralized Mixture-of-Experts. arXiv preprint arXiv:2002.04013, 2020.
[7] William Fedus, Barret Zoph, Noam Shazeer, et al. Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity. arXiv preprint arXiv:2101.03961, 2021
[8] Sai Praneeth Karimireddy, Lie He, Martin Jaggi, et al. Learning from History for Byzantine Robust Optimization. arXiv:2012.10333, 2020
[9] Eduard Gorbunov, Alexander Borzunov, Michael Diskin, Max Ryabinin, et al. Secure Distributed Training at Scale. arXiv:2106.11257, 2021
[10] Paul Sztorc, Peer-to-Peer Oracle System and Prediction Marketplace -Truthcoin
[11] https://github.com/learning-at-home/hivemind